Chatbot Instructions
How do you run a Large Language Model on a server that only has 1 gb of RAM and 20 gb of hard drive space? Basically: you set up a T4 run-time on Google Colab, tell it to use its GPU for computation, download/run an Ollama server, then expose that server to the internet using an ngrok tunnel. Then on THIS server, run a parallel instance of Ollama, feed commands to the Google Colab instance through the ngrok tunnel, and set up a Docker container running OpenWebUI to make for an easier user-experience. We will do all of that in the 2 steps below:
Step 1:
Click the following link: https://colab.research.google.com/drive/14o7Ck8dFI89SE-q831uK4aajHvWiLoIw. This will open up a Google Colab page (on your Google Account) that will allow you to run code that I've written directly on Colab servers. This code will install an LLM model on their servers, which will be accessible by this server.
- Click on the icon that looks like a key on the left-hand part of the screen. Click "+ Add New Secret" and use "NGROK_AUTH_TOKEN" for the name and "2taO8x8VURZ7vnltuGt2fieR1CB_K85eAfpPSPyApXNKqY54" for the secret. Click the slider on Notebook access
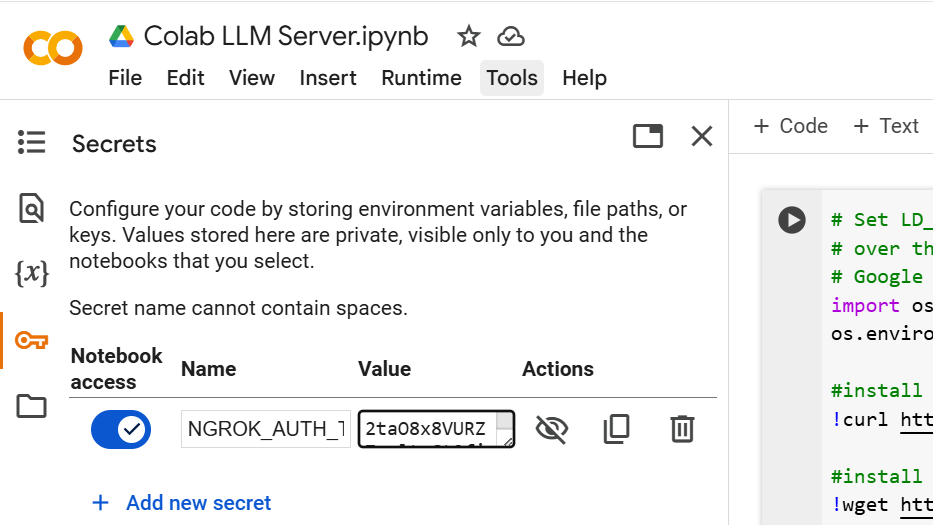
- Run the script, either by pressing CTRL+F9, or by manually pressing play on each of the code blocks. It should take about 3 minutes total to run...about 1 minute for the first code block and 2 minutes for the 2nd code block.
- When everything is finished, you should see a terminal that looks like this:
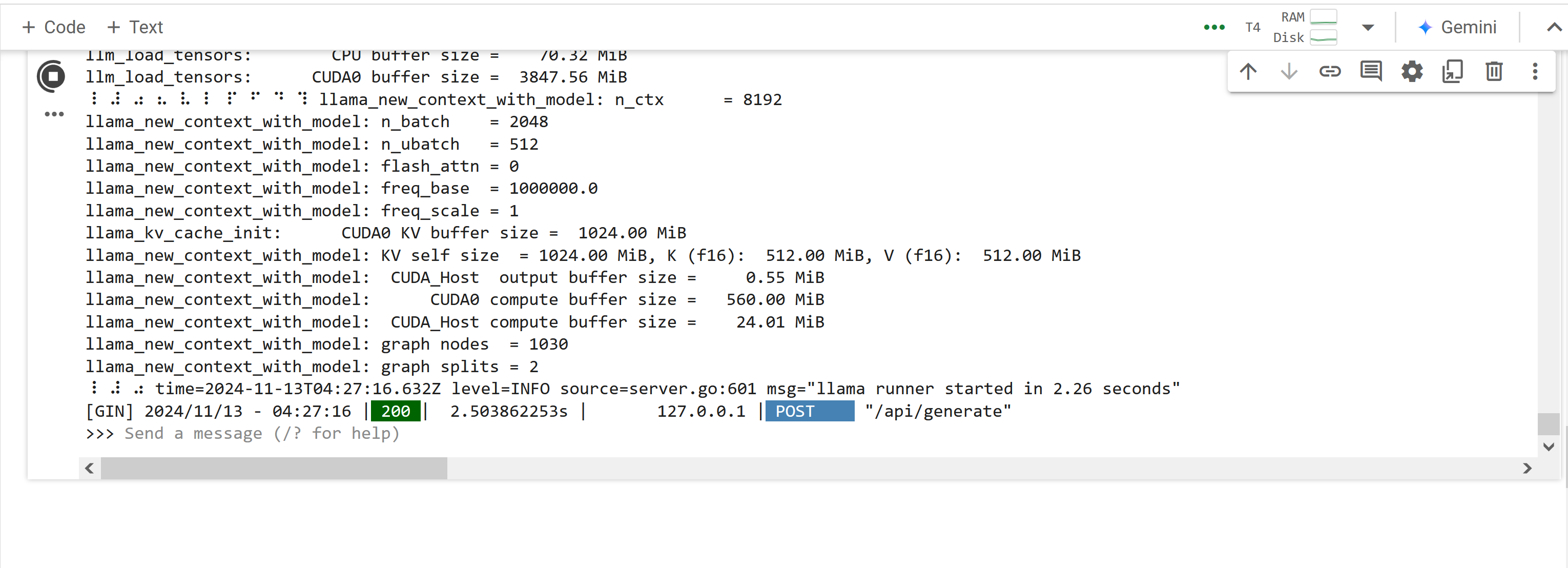
- After seeing this, KEEP THE TAB OPEN. The Google Colab "play" button will keep spinning. This means that Colab is actively running the LLM model.
Step 2:
After ensuring that the Google Colab Script is actively running, click on the link below. You should login in with:
USER: guest@qdtruong.com
PASSWORD: 123456
http://165.227.217.35:3000/?temporary-chat=true
You should now be able to converse with the LLM model you just created on Google Colab! REMEMBER TO DELETE YOUR CHATS AFTER YOU FINISH.